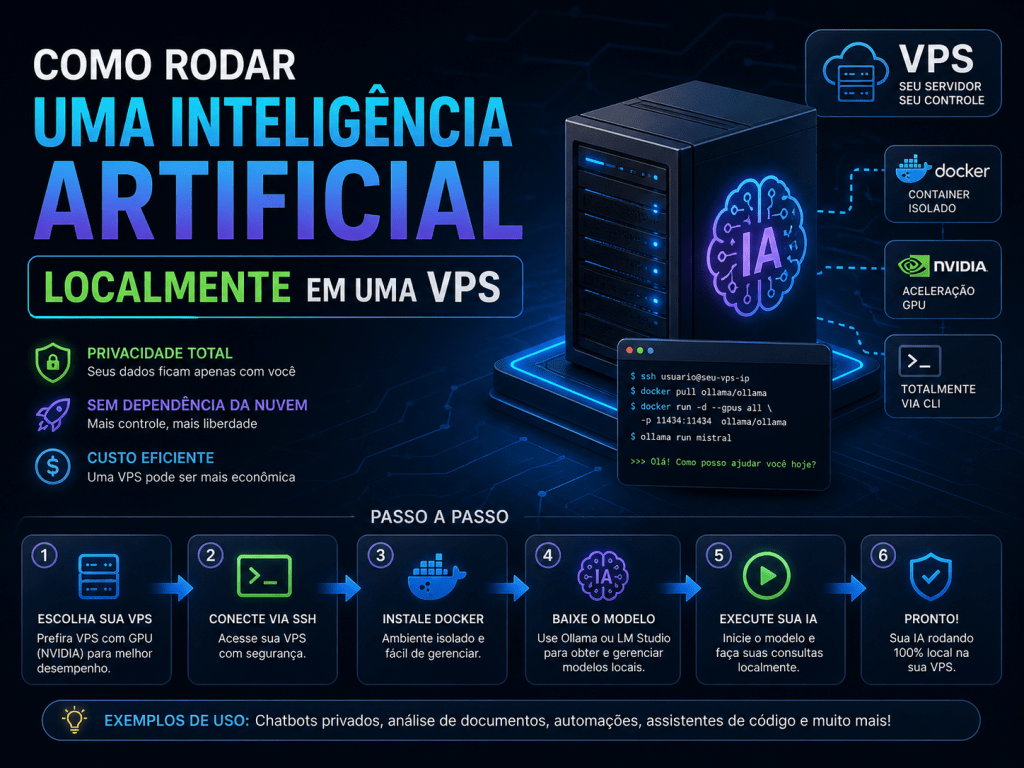
Hospedar sua própria inteligência artificial deixou de ser privilégio de grandes corporações com datacenters milionários. Com o amadurecimento de ferramentas open source como Ollama e Open WebUI, qualquer pessoa pode montar um ecossistema completo de IA em um servidor virtual privado (VPS) — com privacidade total, tokens ilimitados e custo fixo previsível.
Neste guia, você vai aprender o passo a passo completo: desde a escolha do hardware até a instalação do Ollama, configuração da interface web Open WebUI, seleção dos melhores modelos para cada cenário e, claro, as medidas essenciais de segurança e otimização. Vamos direto ao ponto.

Por que Rodar IA em uma VPS?
Antes de colocar a mão no terminal, vale entender as vantagens dessa abordagem:
- Privacidade absoluta: Seus dados e prompts nunca saem do seu servidor — essencial para setores como saúde, finanças e jurídico.
- Custo previsível: Enquanto APIs de IA cobram por token consumido, a VPS tem valor fixo mensal. Para volumes médios de uso, a economia pode chegar a 60-80%.
- Sem limites artificiais: Nada de “você atingiu o limite de mensagens”. O uso é restrito apenas pelo hardware contratado.
- Controle total: Você decide quais modelos usar, quando atualizá-los e como integrá-los a outras ferramentas self‑hosted, como o n8n.
Uma VPS funciona perfeitamente para inferência (uso de modelos já treinados) e fine‑tuning leve. Para treinar modelos do zero, você precisaria de infraestrutura com GPU dedicada.
Pré‑Requisitos de Hardware e Software
O Mínimo Recomendado
| Recurso | Mínimo | Recomendado |
|---|---|---|
| CPU | 4 vCPUs (x86_64) | 8+ vCPUs |
| RAM | 16 GB | 32 GB ou mais |
| Armazenamento | 50 GB SSD | 100 GB NVMe |
| Sistema Operacional | Ubuntu 22.04 / 24.04 | Ubuntu 24.04 LTS |
| GPU (opcional) | — | NVIDIA com 8 GB+ VRAM |
Esses valores são o ponto de partida para rodar modelos de 7 bilhões de parâmetros com quantização de 4 bits (q4_K_M), que ocupam cerca de 4‑5 GB de RAM.

Qual VPS Escolher?
O mercado oferece diversas opções. Considere:
- Hostinger: Planos a partir de R$ 54,99/mês para 4 vCPUs, 16 GB RAM e 200 GB NVMe. Já oferece template pronto com Ollama + Open WebUI + Llama 3.1 pré‑instalados.
- DigitalOcean: Ideal para desenvolvedores que querem flexibilidade total.
- Hetzner: Excelente custo‑benefício, especialmente nos planos com GPU dedicada.
- AWS EC2 / Azure: Para quem precisa de GPU sob demanda, instâncias como
g6e.xlarge(NVIDIA L4) funcionam muito bem com Ollama.
Dica: Se você não tem GPU, não se preocupe — modelos otimizados rodam em CPU, apenas com latência maior.
Passo a Passo da Instalação
Método 1: Instalação Direta no Ubuntu (Recomendado para Iniciantes)
- Conecte‑se via SSH ao seu VPS:bashssh root@seu-ip
- Atualize o sistema:bashsudo apt update && sudo apt upgrade -y
- Instale o Ollama com o script oficial:bashcurl -fsSL https://ollama.com/install.sh | sudo sh
- Verifique a instalação:bashollama –version
- Baixe seu primeiro modelo (ex.: Llama 3.1 8B):bashollama pull llama3.1:8b
- Teste no terminal:bashollama run llama3.1:8b
Pronto! O Ollama já está respondendo. Por padrão, a API fica em http://localhost:11434.

Método 2: Docker Compose (Para Maior Controle)
O Docker isola o ambiente e facilita atualizações. Crie um arquivo docker-compose.yml:
version: '3.8'
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
ports:
- "11434:11434"
environment:
- OLLAMA_KEEP_ALIVE=10m
- OLLAMA_NUM_THREADS=4 # Ajuste conforme seus núcleos
- OLLAMA_MAX_LOADED_MODELS=2
volumes:
- ./ollama_data:/root/.ollama
restart: unless-stopped
deploy:
resources:
limits:
cpus: '4.0'
memory: 8G
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "3000:8080"
environment:
- OLLAMA_BASE_URL=http://ollama:11434
volumes:
- ./open-webui_data:/app/backend/data
restart: unless-stopped
depends_on:
- ollama
Suba os serviços:
docker compose up -d
Acesse http://seu-ip:3000 para usar o chat via navegador.
Método 3: Templates Prontos (Caminho Mais Rápido)
Provedores como a Hostinger já oferecem templates com tudo configurado — Docker, Ollama, Open WebUI e o modelo Llama 3.1. Basta selecionar o template “Ollama” ao criar o VPS e aguardar 10 minutos. Ao final, você acessa a interface web diretamente.

Interface Gráfica: Open WebUI
O Open WebUI entrega uma experiência visual muito similar ao ChatGPT, mas 100% auto‑hospedada. Principais recursos:
- Chat multimodelo: Troque entre diferentes LLMs com um clique.
- Upload de arquivos: Processamento de documentos, PDFs, imagens (modelos multimodais).
- Histórico persistente: Conversas armazenadas no seu servidor.
- Gestão de usuários: Crie contas para sua equipe com permissões personalizadas.
- Conexão com APIs externas: Combine modelos locais com serviços como Gemini 2.5 Flash para tarefas pesadas — o melhor dos dois mundos.
Quais Modelos Escolher para Sua VPS?
A escolha do modelo depende do seu hardware e do idioma. Aqui está um resumo prático (todos quantizados em 4 bits):
| Modelo | RAM Necessária | Pontos Fortes |
|---|---|---|
| Llama 3.1 8B | ~5 GB | Equilíbrio geral, melhor ecossistema e tutoriais |
| Qwen 2.5 7B/14B | 4‑10 GB | Excelente para português e tarefas de código (versão Coder) |
| DeepSeek‑R1 14B | ~10 GB | Raciocínio lógico‑matemático excepcional |
| Mistral Small | ~5 GB | Leve e rápido, ideal para VPS sem GPU |
| Gemma 3 7B | ~5 GB | Boa performance em CPU para tarefas simples |
Dica para falantes de português: O Qwen 2.5 foi treinado com grande volume de dados multilíngues e apresenta resultados superiores em nosso idioma quando comparado a modelos do mesmo tamanho.
Para baixar qualquer um deles:
ollama pull qwen2.5:14b
Otimização de Performance
Ajuste de Threads (CPU)
Defina a variável de ambiente OLLAMA_NUM_THREADS com o número de núcleos físicos do seu processador. Isso evita sobrecarga desnecessária e reduz a latência:
export OLLAMA_NUM_THREADS=4
No Docker, já incluímos essa variável no docker-compose.yml.

Contexto e Quantização
- Reduza o tamanho da janela de contexto (
num_ctx) se não precisar de conversas muito longas. O padrão é 2048 tokens; diminuir para 1024 libera RAM. - Prefira sempre modelos quantizados (
q4_K_M). Eles oferecem o melhor equilíbrio entre qualidade de resposta e consumo de memória.
GPU vs CPU
Se você dispõe de GPU NVIDIA, instale os drivers e o nvidia-container-toolkit. O Ollama ativa a aceleração automaticamente. Em setups sem GPU, foque em modelos de até 8B com baixa quantização — eles rodam a velocidades aceitáveis (5‑15 tokens/segundo).
🔒 Segurança: Não Deixe Sua IA Exposta
⚠️ Alerta: Por padrão, o Ollama escuta em 0.0.0.0:11434, o que significa que qualquer pessoa na internet pode acessar sua API se você não configurar o firewall corretamente.
Medidas Essenciais
- Feche a porta 11434 do mundo externo:bashsudo ufw allow 22/tcp # SSH sudo ufw allow 3000/tcp # Open WebUI sudo ufw deny 11434 # Bloqueia acesso externo à API Ollama sudo ufw enableApenas o Open WebUI (porta 3000) precisa ficar acessível.
- Use um proxy reverso com autenticação:
Coloque o Nginx ou Caddy na frente do Open WebUI e adicione autenticação básica ou OAuth2. - Não use senhas padrão:
Na primeira execução do Open WebUI, crie imediatamente uma conta administrador com senha forte. - Mantenha HTTPS:
Com o Certbot (Let’s Encrypt), você obtém SSL gratuito em minutos:bashsudo apt install certbot python3-certbot-nginx -y sudo certbot –nginx -d seu-dominio.com

Conclusão
Montar seu próprio servidor de IA em uma VPS é mais simples do que parece — e os benefícios em privacidade e economia de custos são reais. Com Ollama, Open WebUI e um modelo bem escolhido, você tem em mãos uma plataforma privada, escalável e pronta para produção.
O ecossistema open source não para de evoluir: projetos como RamaLama (gerenciamento de containers de IA) e vLLM (inferência de alto desempenho) já apontam para um futuro onde rodar IA própria será tão trivial quanto instalar um app no celular.
Que tal começar hoje? Em menos de 30 minutos você transforma sua VPS em uma central de inteligência artificial — sem depender de ninguém.
