Neste guia abrangente, você vai descobrir como transformar seus modelos de inteligência artificial em serviços acessíveis, escaláveis e seguros. Vamos explorar desde os conceitos básicos de hospedagem de APIs de IA até a implementação prática com ferramentas modernas, comparando as principais plataformas do mercado e as melhores estratégias para cada cenário. Seja você um desenvolvedor iniciante ou um arquiteto de software experiente, este artigo fornecerá o conhecimento necessário para hospedar suas próprias APIs de IA com confiança.
1. Introdução: O que são APIs de IA e por que hospedá-las?
Uma API de hospedagem de LLM é um serviço baseado em nuvem que fornece acesso contínuo a grandes modelos de linguagem por meio de interfaces de programação, abstraindo toda a complexidade da infraestrutura. Em termos práticos, é a forma como você disponibiliza seu modelo de IA para que outras aplicações possam consumi-lo remotamente. Os motivos para hospedar sua própria API de IA são diversos: privacidade absoluta dos dados, eliminação de custos recorrentes com assinaturas, tokens ilimitados e independência tecnológica.

2. Tipos de Modelos e APIs de IA
| Categoria | Exemplos de Modelos | Casos de Uso Típicos |
|---|---|---|
| LLMs (Large Language Models) | GPT-4, Llama 3, Gemma, Mistral | Geração de texto, chatbots, análise de documentos |
| SLMs (Small Language Models) | Phi-3, Granite, Gemma 2 | Dispositivos com hardware limitado, inferência local |
| Visão Computacional | YOLO, ResNet, ViT, DINOv2 | Detecção de objetos, classificação de imagens, OCR |
| Áudio e Fala | Whisper, Bark, WaveNet | Transcrição, síntese de voz, tradução em tempo real |
| Embeddings e RAG | text-embedding-3, BGE, E5 | Busca semântica, sistemas de recomendação, Q&A com documentos |
| Modelos Multimodais | GPT-4o, Gemini Flash, LLaVA | Análise combinada de texto, imagem e áudio em um único modelo |
O ecossistema de IA oferece hoje uma ampla variedade de modelos com diferentes portes e especialidades. Os Large Language Models (LLMs) são a escolha ideal para tarefas complexas de raciocínio e compreensão contextual profunda, enquanto os Small Language Models (SLMs) são particularmente adequados para execução local em dispositivos com recursos limitados. Modelos como o Whisper dominam a transcrição de áudio, e arquiteturas de visão computacional como o ResNet são amplamente utilizadas em servidores de produção.

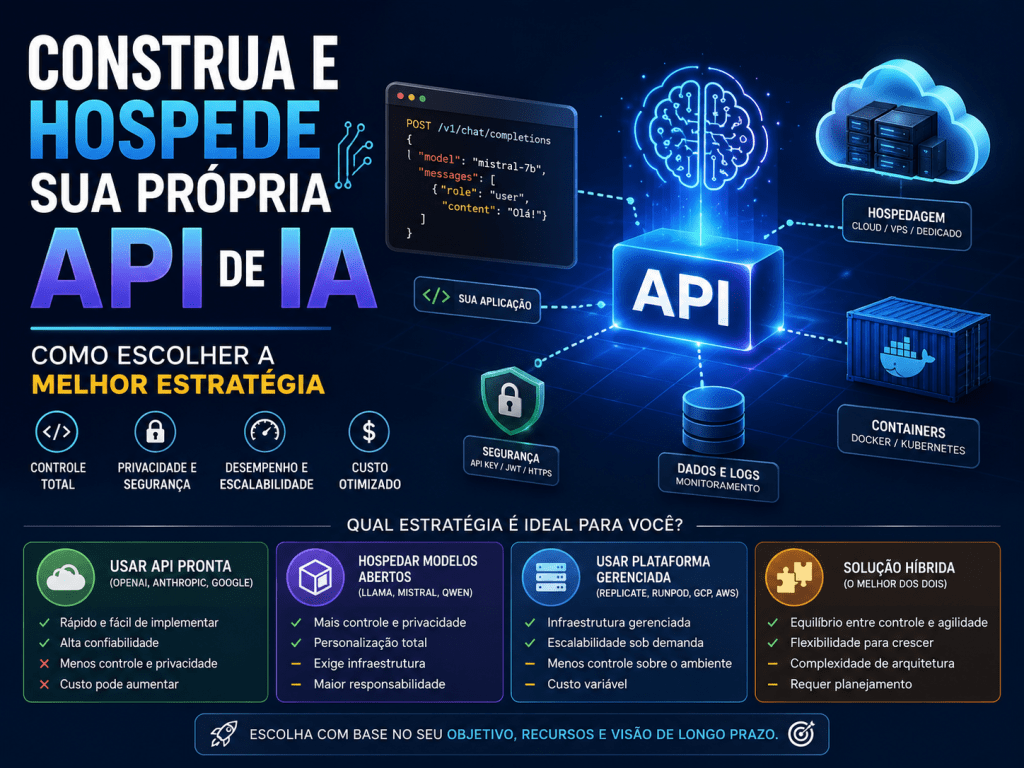
3. Estratégias de Hospedagem: Local vs. Nuvem
A decisão entre hospedar sua IA localmente ou na nuvem é estratégica e define a arquitetura de todo o seu sistema. Cada modelo tem suas vantagens e desafios específicos:
Hospedagem Local (On-Premise)
Manter os dados no dispositivo oferece vantagens significativas em segurança e privacidade, tornando essa abordagem ideal para setores com requisitos rigorosos de conformidade, como saúde e finanças. A latência é reduzida, pois os dados não precisam ser enviados pela rede, resultando em tempos de resposta mais rápidos. No entanto, o desempenho é limitado pelas capacidades de hardware disponíveis, exigindo investimento significativo em GPUs e infraestrutura especializada.
Hospedagem em Nuvem
As plataformas de nuvem, como Azure AI Services e Google Cloud Vertex AI, oferecem recursos escaláveis — você usa tanta potência computacional quanto precisar e paga apenas pelo que consumir. Os provedores cuidam das atualizações de segurança e manutenção, eliminando a sobrecarga operacional da gestão de infraestrutura. Em contrapartida, os dados precisam ser transferidos para a nuvem, o que pode levantar preocupações de privacidade e conformidade regulatória. A tabela a seguir resume os principais fatores de decisão:
| Fator | Hospedagem Local | Hospedagem em Nuvem |
|---|---|---|
| Privacidade | Alta — dados não saem do dispositivo | Depende do provedor e da configuração |
| Latência | Baixa — processamento local | Média/Alta — depende da rede |
| Escalabilidade | Baixa — limitada ao hardware disponível | Alta — recursos elásticos sob demanda |
| Custo Inicial | Alto — investimento em servidores e GPUs | Baixo — pagamento por uso |
| Manutenção | Responsabilidade total do desenvolvedor | Gerenciada pelo provedor |
| Personalização | Total — acesso direto ao hardware | Parcial — depende dos serviços oferecidos |
Abordagem Híbrida
Muitas organizações adotam uma estratégia híbrida inteligente: executam modelos locais para operações sensíveis e de baixa latência, enquanto recorrem à nuvem para cargas de trabalho intensivas e escaláveis. Um excelente exemplo prático é conectar sua infraestrutura local a APIs externas para complementar capacidades — como utilizar o Gemini 2.5 Flash através do Open WebUI para gerar código e textos pesados, mantendo a experiência centralizada em sua interface privada.

4. Principais Plataformas e Ferramentas para Hospedar APIs de IA
O mercado atual oferece diversas opções para hospedar suas APIs de IA, cada uma com características próprias que atendem a diferentes necessidades e níveis de expertise:
SiliconFlow: Plataforma de nuvem de IA completa que oferece API compatível com OpenAI e ajuste fino gerenciado. Em benchmarks recentes, entregou velocidades de inferência até 2,3× mais rápidas e 32% menor latência comparada às principais plataformas concorrentes.
Hugging Face: Hub de modelos open-source com endpoints de inferência gerenciados. Ideal para prototipagem rápida e experimentação com modelos da comunidade, funciona como ponto de partida para muitos projetos.
Groq: Plataforma otimizada para inferência ultrarrápida utilizando hardware proprietário LPU (Language Processing Unit). Excelente para cenários que exigem latência extremamente baixa.
Google Vertex AI: Plataforma gerenciada do Google Cloud que suporta tanto modelos proprietários quanto personalizados, com integração nativa aos serviços Google Cloud e ferramentas de MLOps.
AWS Bedrock: Serviço serverless da Amazon que fornece acesso a modelos de fundação das principais empresas de IA. Permite personalização com seus próprios dados e integração com o ecossistema AWS.
Ollama + vLLM: Ferramentas open-source para auto-hospedagem de LLMs em infraestrutura própria, ideais para quem busca controle total sobre o ambiente de execução.

| Ferramenta | Tipo | Destaque | Ideal para |
|---|---|---|---|
| FastAPI | Framework Python | Alta performance, async, Swagger integrado | Construção de APIs RESTful para modelos ML |
| Ollama | Motor de inferência | Simplicidade, execução local de LLMs | Auto-hospedagem de modelos open-source |
| vLLM | Servidor de inferência | Alta throughput, batching eficiente | Produção com múltiplos usuários simultâneos |
| Docker | Containerização | Portabilidade, isolamento de ambiente | Deploy consistente em qualquer plataforma |
| Kubernetes | Orquestração | Auto-scaling, rolling updates, health checks | Ambientes de produção corporativos |
| MLflow | MLOps | Versionamento de modelos, tracking de experimentos | Gestão do ciclo de vida completo dos modelos |
Além das plataformas gerenciadas, ferramentas como Ollama, vLLM e FastAPI são fundamentais para desenvolvedores que preferem construir e gerenciar sua própria infraestrutura de APIs de IA. O Docker oferece portabilidade e facilidade de deploy, enquanto o Kubernetes gerencia clusters de contêineres com auto-scaling e alta disponibilidade para ambientes corporativos.

5. Construindo e Implantando sua API de IA
5.1 Setup Local com FastAPI
FastAPI é um framework Python moderno e assíncrono que se tornou o padrão de facto para construção de APIs de IA. O exemplo abaixo demonstra um endpoint funcional de chat com LLM, inspirado nas melhores práticas da comunidade:
from fastapi import FastAPI
from pydantic import BaseModel, Field
import os
# Inicialização do app
app = FastAPI(title="API de Chat com IA", version="1.0.0")
# Schemas de validação
class ChatRequest(BaseModel):
question: str = Field(..., min_length=3)
model: str = Field(default="llama3")
class ChatResponse(BaseModel):
response: str
# Endpoint principal
@app.post("/chat", response_model=ChatResponse)
async def chat_endpoint(payload: ChatRequest):
# Em produção, substituir pela chamada ao seu LLM
return ChatResponse(response=f"Processado: {payload.question}")
# Health check
@app.get("/health")
async def health():
return {"status": "operacional"}
5.2 Execução e Documentação
Para executar, utilize:
uvicorn app.main:app --reload --host 0.0.0.0 --port 8000
Acesse a documentação interativa gerada automaticamente pelo Swagger UI em http://localhost:8000/docs e a documentação alternativa ReDoc em http://localhost:8000/redoc.
5.3 Implantação com Docker
Para ambientes de produção, a containerização garante portabilidade e consistência:
FROM python:3.11-slim WORKDIR /app COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY . . EXPOSE 8000 CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]
docker build -t minha-api-ia . docker run -p 8000:8000 minha-api-ia

5.4 Auto-Hospedagem com Ollama
O Ollama é o motor que roda silenciosamente no servidor, executando modelos localmente com instalação simplificada. Um guia prático:
- Instale o Ollama no servidor Linux:
curl -fsSL https://ollama.com/install.sh | sh
- Baixe e execute um modelo:
ollama pull llama3.2 ollama serve # Inicia o servidor da API
- A API REST do Ollama fica disponível em
http://localhost:11434e pode ser consumida diretamente ou integrada ao FastAPI como backend de inferência.
6. Segurança em APIs de IA
A segurança é crítica em APIs que processam dados sensíveis. A autenticação consiste em verificar se o usuário é quem diz ser, validando sua identidade. No universo de APIs, esse processo pode ser realizado combinando login e senha, usando tokens como OAuth ou JWT, ou solicitando chaves de API que atuam como identidade digital.
Já a autorização determina os níveis de acesso e permissões que o usuário terá. Após o usuário provar sua identidade por meio da autenticação, o sistema permite que apenas as áreas apropriadas e os dados autorizados possam ser acessados. A união desses dois mecanismos cria uma barreira sólida que é praticamente impossível de ser contornada.
Melhores práticas essenciais:
- Utilizar OAuth 2.0: permite que aplicativos acessem recursos em nome de um usuário, fornecendo um token de acesso em vez de compartilhar senhas diretamente
- Implementar Rate Limiting: prevenção de abuso com limites de requisições por minuto. O status HTTP 429 (Too Many Requests) é retornado quando o limite é excedido
- Criptografar tokens e chaves de API: proteger credenciais em trânsito usando TLS 1.3 e em repouso com criptografia adequada
- Autenticação Multifator (MFA): requer que usuários provem sua identidade de mais de uma maneira, combinando algo que sabem (senha) com algo que possuem (código SMS)
- Sanitização de respostas: limpar ou mascarar dados sensíveis como e-mails, CPF, CNPJ e números de telefone antes de retornar ao usuário, utilizando expressões regulares
- Validação de entradas com Pydantic: modelos de dados que validam automaticamente o corpo da requisição, retornando erros estruturados como HTTP 422 (Unprocessable Entity) quando dados inválidos são enviados

7. Gerenciamento de Custos
API de IA não é “paga uma vez e pronto”: cada chamada ao modelo tem um preço, e dependendo do uso, isso pode ficar caro rapidamente. Prever custos é essencial para evitar surpresas desagradáveis.
A cobrança de IA é baseada em tokens — que podem ser palavras inteiras, pedaços de palavras, números ou símbolos. Em português, um token costuma ter de 3 a 3,5 caracteres em média. Para estimar custos com precisão, você precisa entender o tamanho médio do prompt, o volume de uso e o comportamento dos usuários.
Estratégias práticas de otimização econômica:
- Comece sempre pelo modelo mais barato que resolva o problema; só migre para opções mais caras se houver ganho real de qualidade ou raciocínio
- Configure o sistema para “dar escape” quando não souber responder — isso evita respostas inventadas e economiza tokens valiosos
- Hospedar modelos localmente com ferramentas como Ollama pode reduzir custos operacionais em cenários de alto volume, especialmente quando combinado com modelos quantizados que oferecem desempenho “suficientemente bom” a menor custo
8. Casos Práticos e Exemplos de Arquitetura
8.1 Aplicação RAG (Retrieval Augmented Generation)
Aplicações RAG permitem que modelos de IA consultem documentos proprietários antes de responder, combinando busca semântica com geração de texto. Um exemplo completo utiliza FastAPI, Azure OpenAI e Azure AI Search, demonstrando como implementar uma interface de chat que recupera informações de seus próprios documentos e fornece respostas contextualizadas com citações adequadas.
8.2 Arquitetura de Produção com Docker Compose
Um ambiente completo de produção pode ser orquestrado com Docker Compose, integrando vLLM para servir o modelo local, FastAPI como backend, ChromaDB para armazenamento de vetores e Streamlit como interface de usuário. Esta arquitetura modular permite que cada componente seja escalado independentemente.
9. Conclusão
Hospedar suas próprias APIs de IA é uma jornada que começa com a escolha da estratégia de implantação correta (local, nuvem ou híbrida), passa pela seleção das ferramentas adequadas (FastAPI, Ollama, Docker) e se consolida com práticas sólidas de segurança e gestão de custos. O ecossistema atual oferece opções para todos os perfis: desde plataformas gerenciadas como SiliconFlow e Hugging Face até soluções totalmente auto-hospedadas com Ollama e Kubernetes.
Comece com um protótipo simples usando FastAPI e expanda gradualmente para uma arquitetura de produção robusta com containerização e orquestração, sempre mantendo a segurança e a eficiência econômica como prioridades. O conhecimento e as ferramentas estão ao seu alcance — o próximo passo é colocar em prática e transformar seus modelos de IA em serviços de valor real.
Descubra mais sobre Guia do Host
Assine para receber nossas notícias mais recentes por e-mail.
